Perl文章整理
Perl语言介绍 http://www.einverne.tk/2012/09/perl-introduction.htmlPerl语言基本语法 http://www.einverne.tk/2012/09/perl-basic-syntax.html
Perl数组与哈希 http://www.einverne.tk/2012/09/perl-array-hash.html
Perl文件操作与函数 http://www.einverne.tk/2012/09/perl-file-operation-and-function.html
Perl模式匹配 http://www.einverne.tk/2012/10/perl-pattern-matching.html
http://www.einverne.tk/2012/11/perl.html
Perl复杂数据结构 http://www.einverne.tk/2012/11/perl-data-structure.html
Perl基本输入输出 http://www.einverne.tk/2012/11/perl-stdin.html
Perl模块 http://www.einverne.tk/2013/02/perl-modules.html
Perl练习 http://www.einverne.tk/2012/09/perl-exercise.html
Perl需要注意的问题 http://www.einverne.tk/2012/09/perl-attention.html
更多请查看Tag:Perl
Perl模块
一个很好的网站CPAN标准爬虫
#程序功能:给定一个url,自动下载该网页的html
use Encode;
use HTTP::Request;
use LWP::UserAgent;
#给定要抓取的url
$Website='http://kjs.mep.gov.cn/hjbhbz/bzwb/hxxhj/xgjcffbz/index_1.htm';
$ua=new LWP::UserAgent();
$request=new HTTP::Request('GET',$Website);
$response=$ua->request($request);
$str=$response->content;
Encode::_utf8_on($str);
print encode("gb2312",$str);
#下载一个pdf文件
use HTTP::Request::Common;
use LWP::UserAgent;
$ua=new LWP::UserAgent();
$ua->timeout(100);
$url="http://kjs.mep.gov.cn/hjbhbz/bzwb/dqhjbh/jcgfffbz/201203/W020120410332725219541.pdf";
$filespec="W020120410332725219541.pdf";
$response = $ua->request(GET($url),$filespec);
动态程序设计(Perl)语言期末考试
提交要求:程序名和结果文件名按照题目要求命名,所有程序(不要原始数据,不要结果文件)打包到一个压缩文件,文件名命名按照“姓名-学号”格式,压缩包发到perl_*@163.com,本人需要确认发送成功。
一、(50分)编制perl程序1.pl, 给定一个英汉词典 ecdict.txt,该词典格式为:
#英文单词
词性1. 汉语译文1;汉语译文2..
词性2. 汉语译文1;汉语译文2..
#英文单词
词性1. 汉语译文1;汉语译文2..
词性2. 汉语译文1;汉语译文2..
…
请根据此词典,不考虑词性信息,生成一部汉英词典cedict.tx,词典中,以汉语译文为词条,以英文单词为译文,汉语词条汉字拼音序排列,其英文译文按照字母序排列,生成的格式为:
#汉语词1
英文译文1; 英文译文2…
#汉语词2
英文译文1; 英文译文2…
…
二、(50分)
1)编制perl程序2_1.pl,自动下载该html页面,保存名为hao123.txt (10分)
2)编制perl程序2_2.pl,页面中超链接形式为href=”url”,统计该页面中包括该形式超链接的数目,数目输出到屏幕中(15)
3)编制perl程序2_3.pl,统计分类频道内,各个网站信息,用以下格式输出到文件info.txt中 (25)
#优酷网
Class:视频
…
URL: http://www.mmbang.com/
Class:其他
Perl产生随机数
Perl利用函数rand()和srand()为随机数(更确切的说是“伪随机数”)字符串的生成提供了基本的工具。这些函数不是利用加密来提供安 全性的,所以不要利用它们为你金融信息的加密。但是,如果你需要为你的下一个游戏或者动态Web网站的新特性设计一个简单的随机数生成器,那么 rand()和srand()可能就是你所需要的。
函数rand()是真正的随机数生成器,而srand()会设置供rand()使用的随机数种子。函数rand()会返回一个处于0和你所指定的数 值(缺省为1)之间的分数。如果你在第一次调用rand()之前没有调用srand(),那么系统会为你自动调用srand()。
要注意,使用同种子相同的数调用srand()会导致相同的随机数序列被生成。这在有的时候很方便,尤其在游戏编程里,你可能想要重复让随机事件按照精确的相同序列出现。
像下面这样使用rand():
print "Your lucky number for today is: " . int(rand(100) + 1) . " ";
指令:rand
语法:rand($interger)
说明:常和函数srand搭配来取得一随机数,如果没有先宣告stand函数的话,则取出的常数值是一个固定值。这个语法会返回一个介于0和$interger之间的数值,如果$interger省略的话,则会返回一个介于0和1 的数值。
示例:
srand; #要先宣告srand函数,才能产生随机数的效果
$int=rand(10); #$int的值会大于0而且小于10如果希望产生的乱数是整数的话,就要再加上int #这个函数
$int=int(rand(10)); #$int的值是一个整数,且值在0和9之间
--------------------------
$int=rand(10);
$int=int(rand(10));
print "int is $int\n";
运行:
int is 9
再次运行:
int is 7
#可见rand取的是随机数字
实例:我有一个7000行的文本数据,想每次从中随机提取1280行,提取100次,最后生成100个1280行的文本,该如何做?各位请指点。
#!/usr/bin/perl
use strict;
use warnings;
my $data_file = "file1";
print " Generating ...\n";
open FH, "$data_file" or die "Can not open the required file $data_file !";
my @data = <FH>;
close FH;
for (1..100) {
my %hash;
while ((keys %hash) < 1280) {
$hash{int(rand($#data))} = 1;
}
open OUT, ">random$_.txt" or die "Can not open the required file random$_.txt !";
foreach (keys %hash) {
print OUT "$data[$_]";
}
close OUT;
}
print " Complete!\7";
参考资料:http://www.builder.com.cn/2004/0108/105066.shtml
http://blog.appleandroid.com/post/202/
http://bbs3.chinaunix.net/thread-1709378-1-5.html
源文档 <http://blog.sina.com.cn/s/blog_4af3f0d20100izou.html>
Perl基本输入输出
从STDIN输入从标准输入设备读取数据是很容易的,我们已经从第一课上就使用<STDIN>操作符了。例如:
$name=<STDIN>;
在数组环境中,可把所有剩余的行作为一列表返回。如:
@name=<STDIN>;
此时,需要读入多行,然后再对各行分别处理。通常做法是:
while($_=<STDIN>){
chop($_);
#处理$_(每一行)
}
上述程序可简化为:
while(<STDIN>){
chop; #等同于chop($_)
处理$_(每一行)
}
因为$_是许多操作符的缺少变量。
从<>输入
读取输入的另一种方法是使用<>。<>是从Perl程序命令行所指定的文件中读取数据。例如有个文件名为pro1的程序:
#!/usr/bin/perl;
while(<>){
print $_;
}
在UNIX环境中运行:
pro1 file1,file2,file3
此时,将依次读入文件file1,file2,file3中的每一行,然后显示输出。
向STDOUT输出
Perl用print和printf向标准输出设备输出。
print操作符使用字串列表作为参数,依次把每个字符串发送给标准输出,在发送时不插入或改变任何字符。如:
print "网上学园"."欢迎您!" #打印"网上学园欢迎您!"
print 1+2,"你好" #打印"3你好"
printf操作符用于格式化输出,在C语言中有相同的功能。它使用一个参数表,第一个参数是格式控制字符串,它定义了如何打印其余参数。例如:
printf "%10s% 8d%8.2f\n",$a,$b,$c
它的打印结果为:10个字符宽度的$a,空格,8个字符宽度的整数$b,8个字符宽度且包含两位小数的浮点数$c,最后换行。
注意:与前面操作符相类似,printf()的括号可以省略。
Ubuntu下批量添加用户
今天终于再一次感受到Google 的优势,搜出来的第一篇文章就直接能够实现我的效果,之前一个老师用百毒查半天没有解决。Ubuntu自带工具批量添加用户
我们知道一般批量建立用户多是通过shell script,由于许多人没有编程基础,所以用网上查找的脚本批量添加用户遇到了很多麻烦,Linux联盟网站上收集了许多这样的脚本,熟练的用户可以去查找,本文主要是借助Ubuntu Linux自带的工具直接批量添加用户,不需要编写shell脚本批量添加用户帐户的方法。
Ubuntu中自带的工具是newusers 和chpasswd,下边我们通过范例配合newusers和chpasswd命令逐步讲解:
第一步我们需要在文本编辑器中按照/etc/passwd的格式录入帐户信息,我们采用gedit编辑器
sudo gedit /root/account.txt
然后在打开的编辑器中输入相应的内容
student001:x:601:601::/home/sutdent001:/bin/bash
student002:x:602:602::/home/sutdent002:/bin/bash
……..以下内容省略
第二步我们使用newusers命令添加用户,(要以ROOT用户登陆)
sudo newusers</root/account.txt
如果执行过程中没有出现错误信息,我们查看passwd文件和home目录应该已经出现了相应的信息。
第三步执行:
sudo pwunconv
将/etc/shadow产生的shadow密码译码,然后写回/etc/passwd,同时删除shadow文件中的密码字段,取消shawdow密码功能
第四步是建立密码表,以支持chpasswd命令,以下是范例:
sudo gedit /root/password.txt
student001: 4dtgdas
sutdent002: df3456d
………以下省略
第五步将密码倒入相应的文件:
sudo chpasswd</root/password.txt
如果执行没有出现错误,那就会在/etc/passwd文件中以明文显示密码。
最后一步是将passwd的明文密码用pwconv命令编译为shadow文件,这样原来passwd文件中的明文密码将会被x取代。
Sudo pwconv
完毕……
我们知道一般批量建立用户多是通过shell script,由于许多人没有编程基础,所以用网上查找的脚本批量添加用户遇到了很多麻烦,Linux联盟网站上收集了许多这样的脚本,熟练的用户可以去查找,本文主要是借助Ubuntu Linux自带的工具直接批量添加用户,不需要编写shell脚本批量添加用户帐户的方法。
引用:1 2
Perl复杂数据结构-动态语言程序设计7
使用复杂数据结构处理问题字典数据见练习5
#处理字典
open(in,"dict1.txt");
while($Line=<in>)
{
chomp $Line; my %tr=(); #注意这里要使用局部变量以便单独分配内存
($word,$trans)=$Line=~/^(\S+)\=\>(.+)$/g;
@items=$trans=~/([^\;]+)/g;
foreach (@items)
{
$tr{$_}=0;
}
$dict{$word}=\%tr; #值为哈希的哈希
}
close(in);
open(in,"dict2.txt");
while($Line=<in>)
{
chomp $Line;
($word,$trans)=$Line=~/^(\S+)\=\>(.+)$/g;
@items=$trans=~/([^\;]+)/g;
foreach (@items)
{
${$dict{$word}}{$_}=0; #没有的项,perl可以自动创建
}
}
close(in);
#分层遍历输出
foreach $ele (sort keys %dict)
{
print $ele.'=>';
foreach $e (sort keys %{$dict{$ele}})
{
print $e.';';
}
print "\n";
}
Perl——字音对应表的生成。使用了复杂数据结构。语料为transcript.txt
#读取数据
open(in,"transcript.txt");
while($Line=<in>)
{
chomp $Line;
@array=$Line=~/([^\s\>]+)\[([^\]]+)\]/g;
for( $i=0;$i<@array-1;$i++ )
{
if($i%2==0)
{
@tmpChar=$array[$i]=~/(.{2})/g;
@tmpPy=$array[$i+1]=~/(\S+)/g;
for( $j=0;$j<@tmpChar;$j++ )
{
#值为哈希表的哈希表
${$dict{$tmpChar[$j]}}{$tmpPy[$j]}=0;
}
}
}
}
close(in);
#分层遍历输出
foreach $ele (sort keys %dict)
{
print $ele.":\t";
foreach $e (sort keys %{$dict{$ele}})
{
print $e.'; ';
}
print "\n";
}
Perl——历时字频处理任务的答案代码。使用了复杂数据结构。
#用来统计各个词在不同年份中的出现频率,形成词汇的生命曲线
$path="D:\\Documents\\desktop\\lex";
$year=1950;
opendir(DIR,$path);
@files=readdir(DIR);
closedir(DIR);
open(out,">mergedLEXS");
foreach $file (@files)
{
if($file=~/txt$/ )
{
print "is processing $file\n";
$file=~/^(\d+)/;
$year=$1;
$file=$path."\\".$file;
merge($file,$year);
}
}
close(out);
foreach $ele (sort keys %hash)
{
print out $ele."\t";
foreach $e (sort keys %{$hash{$ele}})
{
print out "year".$e.":".${$hash{$ele}}{$e}."\t";
}
print out "\n";
}
sub merge
{
my ($inp,$jahr)=@_;
open(in,"$inp");
while(<in>)
{
chomp;
$_=~/^(\S+)\s+(\S+)/;
${$hash{$1}}{$jahr}=$2;
}
close(in);
}
Perl模式匹配-动态语言程序设计6
成语文本四字成语[成语拼音空格隔离12345代表四声和轻音]
只打印出中文成语
if(/(.+)\[/){
}
或者用替换
s/(.*)\[.*\]/$1/;
s/\[.*\]//;
print "$_\n";
取得文本中拼音表
if(/.*\[(.*)\]/){
@PY=split(" ",$1);
foreach (@PY){
$hash{$_}++;
}
}
foreach (sort keys %hash){
print "$_\n";
}
#一句中文本
<Eng>英文翻译
<PY>汉语分词[拼音空格分离]
<Wav>0001Ex.wav
取得拼音表
if(/<PY>(.*)/){
@Item=$1=~/\S+/;
foreach(@Item){
if(/(.+)\[/){
$hash{$1}++;
}
}
}
foreach (sort keys %hash){
print "$_\n";
}
@Item=$1=~/(\S+)\[/g;
foreach(@Item){
$hash{$_}++;
}
~/([a-z]+)\d/g;
@pinyins=/[a-z]+[1-5]\d/g;
/(.*)\[.*2\]/or/(.*)\[.*4\]/
if(/<Eng>(.*)/){
@Item=$1=~/\S+/g;
foreach(@Item){
tr/[a-z]/[A-Z]/;
S/[\.\"\{\}]//g;
$hash{$_}++;
}
}
练习9 统计语料中的声调出现情况
练习10 从语料中生成索引为拼音的字典
Perl模式匹配-动态语言程序设计5
模式匹配,正则表达式,很牛叉的一个概念,很久以前就听说过只是一直没去看,正好今天Perl语言讲到了这个。$str="abcabacabvdaf1423adsf323";
if($str =~/abc/){
}
ab?c 匹配abc|ac ?表示b出不出现
ab+c >=1个b出现 ab...c
ab*c >=0个b出现 ac|ab..c
ab{n1,n2}c n1<=b出现的次数<=n2
ab{n1}c b出现n1次
ab{,n1}c 最多n1次
ab{n1,}c 至少n1次
总结:匹配出现次数的有 ? + * {n1,n2}
. 表示任意字符
[abc] 表示abc其中一个字符
[^abc] 表示非abc字符
总结:集合符号 单字符 . [] [^]
其他集合
\d 表示0~9任意一个数字
\D 非数字
\s =[ \t\r\n] 隔离符号
\S 非隔离符
/^a/ 以a开头
/a$/ 以a结束
()* *作用于()
模式匹配中的() $1 $2来表示
~/aBc/i 忽略大小写
~/xxx/g 匹配所有
@array=$str=~/a.b/g; 所有符合的串放到数组中
替换
$str=~s/pattern/target/; 将$str串中所有符合pattern的串替换为target串
$str=~s/a.b/ab/;
模式匹配指在字符串中寻找的特定序列的字符。若在该字符串中找到了该模式,则返回true,不匹配则返回false
$string=~/pattern/; #在string中查找是否包含模式pattern的字符串
$string=~m/pattern/; #同上,另外一种表示方法
$string=~m!pattern! ; #pattern中不含转义字符
匹配操作符 =~与 !~
=~检验匹配是否成功:$result = $var =~ /abc/;若在该字符串中找到了该模式,则返回非零值,即true,不匹配则返回0,即false。!~则相反。这两个操作符适于条件控制中,如:
if ($question =~ /please/) {
print ("Thank you for being polite!\n");
}
else {
print ("That was not very polite!\n");
}
模式中的特殊字符
PERL在模式中支持一些特殊字符,可以起到一些特殊的作用。1、字符+
+意味着一个或多个相同的字符,如:/de+f/指def、deef、deeeeef等。它尽量匹配尽可能多的相同字符,如/ab+/在字符串abbc中匹配的将是abb,而不是ab。
当一行中各单词间的空格多于一个时,可以如下分割:
@array = split (/ +/, $line);
注:split函数每次遇到分割模式,总是开始一个新单词,因此若$line以空格打头,则@array的第一个元素即为空元素。但其可以区分是否真有单词,如若$line中只有空格,则@array则为空数组。且上例中TAB字符被当作一个单词。注意修正。
2、字符 []和[^]
[]意味着匹配一组字符中的一个,如/a[0123456789]c/将匹配a加数字加c的字符串。与+联合使用例:/d[eE]+f/匹配def、dEf、deef、dEdf、dEEEeeeEef等。^表示除其之外的所有字符,如:/d[^deE]f/匹配d加非e字符加f的字符串。
3、字符 *和?
它们与+类似,区别在于*匹配0个、1个或多个相同字符,?匹配0个或1个该字符。如/de*f/匹配df、def、deeeef等;/de?f/匹配df或def。
4、转义字符
如果你想在模式中包含通常被看作特殊意义的字符,须在其前加斜线"\"。如:/\*+/中\*即表示字符*,而不是上面提到的一个或多个字符的含义。斜线的表示为/\\/。在PERL5中可用字符对\Q和\E来转义。
5、匹配任意字母或数字
上面提到模式/a[0123456789]c/匹配字母a加任意数字加c的字符串,另一种表示方法为:/a[0-9]c/,类似的,[a-z]表示任意小写字母,[A-Z]表示任意大写字母。任意大小写字母、数字的表示方法为:/[0-9a-zA-Z]/。
6、锚模式
^ 或 \A 仅匹配串首
$ 或 \Z 仅匹配串尾
\b 匹配单词边界
\B 单词内部匹配
例1:/^def/只匹配以def打头的字符串,/$def/只匹配以def结尾的字符串,结合起来的/^def$/只匹配字符串def(?)。\A和\Z在多行匹配时与^和$不同。
例2:检验变量名的类型:
if ($varname =~ /^\$[A-Za-z][_0-9a-zA-Z]*$/) {例3:\b在单词边界匹配:/\bdef/匹配def和defghi等以def打头的单词,但不匹配abcdef。/def\b/匹配def和abcdef等以def结尾的单词,但不匹配defghi,/\bdef\b/只匹配字符串def。注意:/\bdef/可匹配$defghi,因为$并不被看作是单词的部分。
print ("$varname is a legal scalar variable\n");
} elsif ($varname =~ /^@[A-Za-z][_0-9a-zA-Z]*$/) {
print ("$varname is a legal array variable\n");
} elsif ($varname =~ /^[A-Za-z][_0-9a-zA-Z]*$/) {
print ("$varname is a legal file variable\n");
} else {
print ("I don't understand what $varname is.\n");
}
例4:\B在单词内部匹配:/\Bdef/匹配abcdef等,但不匹配def;/def\B/匹配defghi等;/\Bdef\B/匹配cdefg、abcdefghi等,但不匹配def,defghi,abcdef。
7、模式中的变量替换
将句子分成单词:
$pattern = "[\\t ]+";
@words = split(/$pattern/, $line);
8、字符范围转义
E 转义字符 描述 范围
\d 任意数字 [0-9]
\D 除数字外的任意字符 [^0-9]
\w 任意单词字符 [_0-9a-zA-Z]
\W 任意非单词字符 [^_0-9a-zA-Z]
\s 空白 [ \r\t\n\f]
\S 非空白 [^ \r\t\n\f]
例:/[\da-z]/匹配任意数字或小写字母。
9、匹配任意字符
字符"."匹配除换行外的所有字符,通常与*合用。
10、匹配指定数目的字符
字符对{}指定所匹配字符的出现次数。如:/de{1,3}f/匹配def,deef和deeef;/de{3}f/匹配deeef;/de{3,}f/匹配不少于3个e在d和f之间;/de{0,3}f/匹配不多于3个e在d和f之间。
11、指定选项
字符"|"指定两个或多个选择来匹配模式。如:/def|ghi/匹配def或ghi。
例:检验数字表示合法性
if ($number =~ /^-?\d+$|^-?0[xX][\da-fa-F]+$/) {其中 ^-?\d+$ 匹配十进制数字,^-?0[xX][\da-fa-F]+$ 匹配十六进制数字。
print ("$number is a legal integer.\n");
} else {
print ("$number is not a legal integer.\n");
}
12、模式的部分重用
当模式中匹配相同的部分出现多次时,可用括号括起来,用\n来多次引用,以简化表达式:
/\d{2}([\W])\d{2}\1\d{2}/ 匹配:
12-05-92
26.11.87
07 04 92等
注意:/\d{2}([\W])\d{2}\1\d{2}/ 不同于/(\d{2})([\W])\1\2\1/ ,后者只匹配形如17-17-17的字符串,而不匹配17-05-91等。
13、转义和特定字符的执行次序
象操作符一样,转义和特定字符也有执行次序:
特殊字符 描述
() 模式内存
+ * ? {} 出现次数
^ $ \b \B 锚
| 选项
14、指定模式定界符
缺省的,模式定界符为反斜线/,但其可用字母m自行指定,如:
m!/u/jqpublic/perl/prog1! 等价于/\/u\/jqpublic\/perl\/prog1/
注:当用字母'作为定界符时,不做变量替换;当用特殊字符作为定界符时,其转义功能或特殊功能即不能使用。
15、模式次序变量
在模式匹配后调用重用部分的结果可用变量$n,全部的结果用变量$&。
$string = "This string contains the number 25.11.";
$string =~ /-?(\d+)\.?(\d+)/; # 匹配结果为25.11
$integerpart = $1; # now $integerpart = 25
$decimalpart = $2; # now $decimalpart = 11
$totalpart = $&; # now totalpart = 25.11
参考:Perl模式匹配
正则表达式注意事项
Perl需注意的问题
字符串连接需要用"." 不能用+
如果运用“+”号,Perl会理解成数值运算,做算术运算。例如:
$a = 12;
$b = '13';
print $a+$b;
输出结果就是 25
print $a.$b;
输出结果为 1213
Perl截取中文字符问题
$str="测试文本";
print substr($str,0,1);
这时候输出了一个"?",这显然不是我们想要的结果。因为在perl中,所有从外部输入的字符串(包括写在程序里的字符串)都会当成字节来处理,"print substr($str,0,1);"这句话只是把"测试文本"的第一个字节取出来,并且用print输出,然而单个字节是不能表示一个中文字符的,所以就输出了"?"。
如果想要上面的程序输出正确的结果,就需要使用decode函数把"测试文本"转换成perl内部字符串,让perl把"测试文本"当成字符串来处理,这样再用"substr($str,0,1);"截取的就不是一个字节,而是一个汉字。
use Encode;
$str=decode('gbk',"测试文本");
print encode('gbk',substr($str,0,1));
Perl练习题(更新完毕)
练习1: 屏幕提示用户输入一个高度值, 并在屏幕上打印出一个相应层数的三角形, 如详细要求中的图示意。

while(1){
print ("please input num:(\"q\" to exit):");
$Inp = ;
chomp($Inp);
if($Inp eq "q"){
last;
}
for($i = 1; $i <= $Inp ; $i++){
for($j = 0; $j< $Inp-$i ; $j++ ){
print(" ");
}
for($j = 0; $j< 2*$i-1 ; $j++){
print("*");
}
print("\n");
}
}
练习1源代码下载 ex1_print_triangle.pl练习2:随机生成含有100道两位数”加/减/乘/除”的数学题, 要求运 算数随机,运算符也随机, 结果保存到文件中。
另,假设用户群体为小学低年级。减法结果不得小于零;除法必须整 除。
$i = 0;
while($i<100){
print ("$Num1-$Num2 = \t");
$i++;
}
}elsif($op > 2.5 and $op<=5){
if($Num1+$Num2<=100){
print ("$Num1+$Num2 = \t");
$i++;
}
}elsif($op >5 and $op <=7.5){
if( $Num1*$Num2 >=100){
print ("$Num1*$Num2 = \t");
$i++;
}
}elsif($op >7.5 and $op <=10){
if($Num2 != 0 and int($Num1/$Num2)==$Num1/$Num2){
print ("$Num1/$Num2 = \t");
$i++;
}
}
}
练习2源代码下载 ex2_print_100_questions.pl练习3:独立编写查词典和词频统计程序。
词典为dict.txt
词频统计的对象是mytext
open(Input , "dict.txt");
while($Line = ){
chomp($Line);
($K,$V) = split("=>",$Line);
$hash{$K} = $V;
}
close(Input);
while(1){
print "Input the word u want to search:(\"q\" to exit)\n";
$Line = ;
chomp($Line);
if($Line eq "q"){
last;
}
if( defined $hash{$Line}){
print "$hash{$Line}\n";
}else{
print "没有找到\n";
}
}
练习3查字典源代码下载 ex3_dict.pldict.txt文件下载
词频统计
open(Input , "mytext");
while($Line = ){
chomp($Line);
foreach $Item( split(" ",$Line) ){
$hash{$Item}++;
}
}
close(Input);
foreach $K(sort keys %hash){
print "$K $hash{$K} \n";
}
练习3词频分析 ex_frequency.pl词频分析用到的mytext
练习4:统计两个文件中共同出现的单词,并输出它们在每个文件中出现 的次数。两个文件在files.rar中。
open(Input , "eng1.txt");
while($Line = ){
chomp($Line);
foreach $Item(split(" ",$Line)){
$hash1{$Item}++;
}
}
close(Input);
open(Input , "eng2.txt");
while($Line = ){
chomp($Line);
foreach $Item(split(" ",$Line)){
if( defined $hash1{$Item}){
$hash2{$Item}++;
}
}
}
close(Input);
foreach $K(sort keys %hash2){
if(defined $hash1{$K}){
print "$K $hash1{$K} $hash2{$K}\n";
}
}
练习4源程序下载 ex4_CountWords.pl
练习4用到的eng1 , eng2
练习5:合并两部词典,要求词条唯一,译文合并。词典见附件
需要合并的两部字典
练习6:输出指定路径中所有重复出现的文件的文件名(文件名包括后缀)和出现次数。
练习7:统计一个目录下文件出现哪些词,每个词出现的总频次.用函数形式,统计每个文件出现的词的情况。
请提交代码和词频表(从高频到低频排序);词频表为文本文件
(.txt);格式举例
寺庙 123
大佛 111
……
详细要求: 射雕英雄传
练习8:统计词典中所有拼音(带音调)出现的频率;
请提交代码和频率表(从高频到低频排列,使用它.txt文档)格式例子:
tian2 111
pai4 134
……
详细要求: IdiomPY
练习9:作业要求: 统计语料中的声调出现情况。输出每种音调的出现次数。
格式为(音调以数字表示)
4 1417
5 773
2 721
1 688
3 667
仅需提交代码。语料为Uebungen.txt
详细要求: 统计语料中的声调出现情况
练习9 统计语料中的声调出现情况
参考答案:
open(iD,".txt");
while($line=<iD>)
{
chomp $line;
if($line=~/^\<PY\>/)
{
@array=$line=~/([0,1,2,3,4,5])/g;
foreach (@array) {
$hash{$_}++;
}
}
}
close(iD);
foreach (sort keys %hash) {
print $_."\t".$hash{$_}."\n";
}
练习10:作业要求: 从语料中生成索引为拼音的字典。语料为Uebungen.txt
格式为:
mang2 茫;茫;忙
leng3 冷
you4 又
jing4 静;净;镜;境
tui3 腿
………
仅需上传代码。
详细要求: 从语料中生成索引为拼音的字典
练习10 从语料中生成索引为拼音的字典
参考答案:
open(iD,"12.txt");
while($line=<iD>)
{
chomp $line;
if($line=~/^\<PY\>/)
{
@array=$line=~/([^\>\s]+)\[([^\]]+)\]/g;
for($i=0;$i<@array;$i++){
if($i%2==1)
{
@py=$array[$i]=~/(\S+)/g;
@hz=$array[$i-1]=~/.{2}/g;
for($j=0;$j<@py;$j++)
{
$hash{$py[$j]}=$hash{$py[$j]}.';'.$hz[$j];
}
}
}
}
}
close(iD);
#tian1 天;天;天;……
open(out,">pyHzDict.txt");
foreach $ele (sort keys %hash) {
@berry=$hash{$ele}=~/([^\;]+)/g;
foreach (@berry) {
$temp{$_}=0;
}
print out $ele."\t";
foreach (sort keys %temp) {
print out $_.';';
}
print out "\n";
%temp=();
}
close(out);
作业11:
作业要求: 生成汉字-拼音表
从IdiomPY.txt(见参考资料-Perl语料)中生成汉字-拼音表(注
意多
音字,需要把所有拼音标出)
格式:
行 xing2;hang2
猪 zhu1;
……
作业12:
根据transcript.txt中拼音信息,生成一个带有拼音的词表(词有多音)
答案:
open(in,"transcript.txt");
while ($line=<in>) {
chomp $line;
if($line=~/^\<PY\>/){
@array=$line=~/([^\>\s]+)\[([^\]]+)\]/g;
#print @array;
#print "\n";
for($i=0;$i<@array-1;$i=$i+2){
@tmpchar=$array[$i]=~/(.{2})/g;
@tmpPY=$array[$i+1]=~/(\S+)/g;
for($j=0;$j<@tmpchar;$j++){
${$dict{$tmpchar[$j]}}{$tmpPY[$j]}=0;
}
}
}
}
close(in);
foreach $ele (sort keys %dict) {
print $ele.": ";
foreach $e(sort keys %{$dict{$ele}}) {
print $e.";";
}
print "\n";
}
练习13:
作业要求: 在练习12所使用语料库中,统计连续的单字(多字词之间、单字
和多字词之间)的转移概率。如全文共有N个单字对。每个单字对
的出现概率为其频次F除以N;
请编程输出语料库中所有的连续单字对的出现概率。
同理,输出语料库中所有的连续单字的拼音对出现的概率。
格式如
之_后 0.0003212
之_前 0.0012345
……
详细要求: 单字转移概率和拼音转移概率
练习14:
作业要求: 实现一个成语接龙游戏;
例如:
由人输入:国富民安,
机器回答:安邦定国
由人输入:……
及其回答:……
(仅仅举例,实际有的词成语词典里未必有)
练习16:
编写一个PDF爬虫,爬取中华人民共和国环保部的环境保护标准。
Perl文件操作与函数-动态语言程序设计4
Perl文件操作
打开一个文件操作
open(FileVar, filename) ;FileVar为文件句柄,filename为文件名
打开方式
- 只读
- open (FileVar, “<File.txt”);
- 写
- open (FileVar, “>File.txt”);
- 添加
- open (FileVar, “>>File.txt”);
if (open(MYFILE, "myfile")) { # here's what to do if the file opened successfully }
unless (open (MYFILE, "file1")) { die ("cannot open input file file1\n"); }
open (MYFILE, "file1") || die ("Could not open file");
die语句语法
关闭文件
close(FileVar);文件打开以后一定要关闭
$File=“File.txt”;
open(FileVar,”>$File”);
…
close();
读文件
$line = <FileVar>;从文件中读一行,包含回车换行。
成功读取返回1;否则返回 0
$line = <STDIN>;
从屏幕读取用户输入一行
@array = < FileVar >;
把文件的全部内容读入数组,文件的每一行(含回车符)为数组的一个元素。
例子:
While ( $Line=<FileVar> ){
chop($Line);
….
}
写文件
print FileOut "Here is an output line.\n";往屏幕上输出
print STDOUT "Here is an output line.\n";
print "Here is an output line.\n";
例子:
open(FileOut,”>Out.txt”)
print FileOut "Here is an output line.\n";
close(FileOut)
测试文件状态
-s 文件大小$Size=-s “file.txt”;
-d 是否为目录
if ( -d “file.txt” ){
…
}
-e 是否存在
if ( -e “file.txt” ){
…
}
-r 是否可读
if ( -r “file.txt” ){
…
}
-w 是否可写
if ( -w “file.txt” ){
…
}
删除文件
unlink(“File.txt”);
文件改名
rename(“old.txt”,”new.txt”);
建立目录
mkdir(“dir1”);
改变当前路径
chdir(“c:/dir1”);
删除目录
rmdir(“c:/dir1”);
得到当前目录
$CurrentDir=cwd();
取得一个目录下所有文件和目录信息
opendir(DIR,"D:\\Tmp\\");
@File=readdir(DIR);
foreach (@File){
print "Dir1:$_";
}
close(DIR);
子程序
子程序即执行一个特殊任务的一段分离的代码,它可以使减少重复代码且使程序易读。PERL中,子程序可以出现在程序的任何地方。定义和调用子程序
hello();sub hello
{
print "hello!";
}
参数传递
@testit=("a","b");
hello("test",@testit);
sub hello
{
my($File,@Array)=@_;
print "$File\n";
print "@Array";
}
变量的有效范围
在函数中定义局部变量
my
sub Function{
my %arrayVar=();
my %mapVar=();
…
}
local
sub Function{
local @arrayVar=();
local %mapVar=();
Function1();
…
}
sub Function1}
print “@arrayVar”;
{
查字典子程序:通过子程序重写了练习3
OpenText("dict.txt");
while(1){
print"input a word(press \'q\' to exit):";
$Line=;#读取输入字符串
chomp($Line);
if($Line eq "q")
{
last; #退出循环
}
else{
search($Line);
}
}
sub OpenText{
my ($file)=@_;
open(In,"$file");
my $Line;
while($Line=){
chomp($Line);
my @item=split("=>",$Line);
if(@item==2){
$hash{$item[0]}=$item[1];
}
}
close(In);
}
sub search{
my($Line)=@_;
if ( defined $hash{$Line} )
{
print "$hash{$Line}\n";
}
}
-------------------------------------------------------------------------------------
指令:die (参考)
语法:die LIST
说明:会把LIST字符串显示出来,并退出程序。常常和 $! 这个代表错误信息变量一起使用。
示例:
open(FILE,"$filename")||die "不能打开文件$!\n; # 如果打开文件失败的话,就会显示出错误的信息,之后再退出程序。
Perl数组和哈希-动态语言程序设计3
继上篇讲到Perl语言的简单变量类型,这篇文章讲Perl语言另外两个变量类型----复杂变量类型。Perl中一共只有三种变量类型,除了上一篇讲到的以 $ 符号开头的简单变量之外,还数组和哈希两种变量。##ReadMore##
数组
数组变量
- 以 @ 开头
- 数组的的元素可以是数值、字符串或两者的混合
数组的赋值
- @array = (2, 3, 4);
- @array = (‘str1’, “\tstr2”, “str3”);
- $str4=“str4”; @ array = (‘str1’, “\tstr2”, $str4);
- @array = (1..3,4,5);
- @day_of_month = ("01".."31")
- @array = (e..f); @array= ($a, $b, @array, $g);
- @array = ();
数组包含元素的个数
- $Size= @array;
访问数组元素与遍历
$array[no];
@array=(1,2,3,4,5); $Element=$array[0];
foreach $Element(@array){print “$Element”;}
for($i=0; $i <@array;$I++){print “$array[$i]”;}
其他赋值操作
- ($First)= @array;
- ($First,$Second)= @array;
- ($First,$Second,@SubAraay)= @array;
- @SubAraay = @array[0,1];
- @Array[0,1] = ("string", 46);
有关数组的操作函数
- push(@Array,$Str) ; #在结尾添加一个元素
- $Str =push(@Array) ; #在结尾删除一个元素
- unshift (@Array, $Str) ; #在头添加一个元素
- $Str = shift (@Array) ; #在头删除一个元素
- @sorted=sort(@Array); #只有在赋值时有效
- @ reversed=reverse(@Array); #只有在赋值时有效
- @array=split(“; ”,$String); #字符串拆解
- $String =join(“;”, @array); #字符串连接
- chop(@array); #对每个元素去掉最后一个字符
- chomp(@array); #对每个元素去掉最后一个换行符
哈希
哈希变量
- 以%开头表示哈希变量
- 集合((key1,value1), (key2,value2),… (keym,valuem))
- Key 为数值或者字符串
- Value 为数值、者字符串或者引用
哈希的赋值
- %Hash=();
- %Ages = ("Michael Caine", 39, "Dirty Den", 34, "Angie", 27);
- @fruit = ("apples",17,"bananas",9,"oranges","none"); %fruitHash = @fruit;
- $var1, $var2, %myarray) = @list
- @Key=keys(%hash);
- @value=values(%hash);
访问哈希表
- $ages{"Michael Caine"}; # Returns 39
- $ages{"Dirty Den"}; # Returns 34
增加元素
$hash{$key}=$value;
删除元素
delete ($Hash{$Key});
查找
if ( defined $hash{$element} ){print “$hash{$element}”;}
遍历
foreach $person (keys %ages){print "$person $ages{$person}\n";}
foreach $person (sort keys %ages){print "$person $ages{$person}\n";}
%records = ("Maris", 61, "Aaron", 755, "Young", 511);
while (($holder, $record) = each(%records)) {print "$holder $record \n";}
Perl语言基本语法-动态语言程序设计2
第一个Perl程序Perl程序的扩展名为 pl
print "Hello world";
程序结构
# the demo program
$str = "hello world";
print "$str/n";
...
Func();
...
sub Func(){
print "this is the function";
}
简单变量类型
变量以$开头整型
十进制 $x = 12345;
8进制 $x = 020;(16)
16进制 $x = 0x20; (32)
浮点数
11.4 、 -0.3 、.3 、 3. 、 54.1e+02 、 5.41e03
字符串
$str = "this is a string";
$str = 'this is a string';
双引号内可以包含转义字符和其他变量
在字符串中包含 $ @ " \ 前面要加转义字符 \
\n new line
\t tab
单引号内就是字符本身,单引号支持多行赋值
在字符串中包含 ‘ 前面要加转义字符 \
简单变量的操作符
算术操作符
+, -, *, **, %, -
整数比较操作符
<, =, >, !=, >=, <=,<=>
赋值操作符
+=.-=,*=,/=,**=,%=,
自增自减操作符
++,--
控制结构
结构块
{an expression;
another expression;
last expression;
}
if语句
if(expression){one expression;
}
if(expression){
an expression;
another expression;
last one;
}then{
....
}
if (expression) {
an expression;
another expression;
last one
} elsif (expression) {
} elsif (expression) {
}else{
}
if语句一定需要花括号包含判断之后的语句块,即使只有一句。Then语句也是一样。
除非语句块
unless (expression) {
an expression;
another expression;
last one
}
=?:语句
$foo = ($j < 0) ? ( - $j ) : $j ;
lvalue = expression ? if_true : if_false ;
循环语句(LOOP)
while循环
while ( expression ) {
statements...
}
# must use braces !!!
while ( not expression ) {
statements...
}
for循环
for ( init ; conditional ; re-init ) {
statements...
}
for ($i=0; $i<10; $i++){
print “$i\n”;
}
while (expression) {
bla...
next;
bla...
}
next相当与C/C++,Java中的continue
while (expression) {
bla...
last;
bla...
}
last相当与break
Perl语言介绍-动态语言程序设计1
Perl语言属于脚本语言,同属于脚本语言的还有PHP,Python,ASP,JSP.而脚本语言具有以下几个特点:
- 解释型语言,需要解析器和虚拟机
- 动态数据,不需要数据类型的声明
- 不需要编译
- 调用库往往是源码
- 功能强大
- 容易学习
- 容易使用
- 开放源代码
- 跨平台
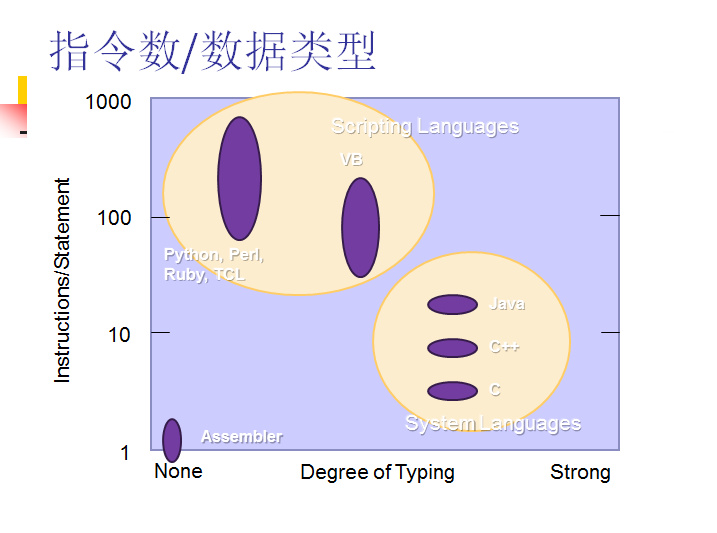
下面举例:
Perl
open(F, $filename); $m = join(“”,Python); @m = split(/\s+/, $m);
F = open(filename, ‘r’) n = F.read().split()例子2
open(File,"脚本语言的应用"); while($Line= ){ chomp($Line); ($Word,$Trans)=split("=>",$Line); $hashDict{$Word}=$Trans; } close(File); print "Pls Input word:\n"; $ForSearch= ); if ( defined $hashDict{$ForSearch} ){ print "$hashDict{$ForSearch}\n"; }else{ print "$ForSearch is not in the dict!\n"; }
软件产品
设计->数据准备->编程实现->软件测试->系统维护->...
软件开发编程=系统语言+脚本语言
国外热,国内冷
Perl(Practical Extraction and Report Language )
- Larry Wall于1987年,为文本处理编写。
- 结合了C,sh, awk和sed的有点。
- 开放源代码,免费下载安装程序。
- 解释性的脚本语言
- Perl不是GUI程序。
- 出色卓越的处理文本能力。
- 特别适合于CGI编程
- 跨平台的编程语言,window,linux…
- 自主内存管理,没有内存泄漏问题。
- 强大便捷的模块化功能。
ActivePerl for Windows http://www.activeperl.com
Perl作用
文本数据的加工处理
- 文本信息抽取
- 格式转换
- 获取统计文本的统计信息
- …
CGI编程
- 处理用户交互的Form表格
- 建立留言版
- BBS
利用Perl扩展模块
- 数据库编程
- 网络编程
- 利用MS的Com组件
- …
Perl相关程序
ActivePerl
- 运行环境
- 下载地址http://www.activeperl.com
PerlWiz
- 开发Perl的集成环境
Perl2exe
- 把perl转换成exe程序
PerlEz
- 在C中调用Perl